串口收发性能测试
对于本框架来说,有一个问题经常会被问到:"LibXR对底层驱动封装之后,性能是否会很差?"
这个问题的答案是:完全不必担心。虽然相比与直接调用厂家SDK(例如hal库,ESP-IDF)提供的API来自行管理DMA等资源,性能会有一定的损失,但是这种损失是很小的,可以忽略不计。下面会附上一些性能测试结果,大家可以自行分析。
测试环境
串口驱动是整个LibXR里面最复杂的部分,性能测试的环境如下:
- STM32F103C8,Cortex-M3 @ 72Mhz
- CH32V307VC, Risc-V @ 144Mhz
- STM32F407IG,Cortex-M4 @ 168Mhz
- Debug模式只有用户代码是-Og优化,HAL库,FreeRTOS,USB等库是-O2优化。Release模式都为-O3优化。
- 使用杜邦线将USART1的TX RX连接起来,数据位为8,停止位为1,无流控��,无奇偶校验
- 收到数据后对整包进行CRC校验,每秒统计发送成功、发送失败和总共校验失败的次数
测试代码
同步方式收发各使用一个线程,虽然上下文切换会带来一些性能损失,但是影响不大。追求极限性能可以使用异步方式收发。
constexpr size_t BUFFER_SIZE = 32;
constexpr size_t BAUDRATE = 2000000;
static uint8_t read_buffer[BUFFER_SIZE], write_buffer[BUFFER_SIZE];
static uint32_t count_read = 0, count_write = 0, count_error = 0;
for (uint32_t i = 0; i < sizeof(write_buffer); i++) {
write_buffer[i] = i;
}
STDIO::write_ = uart_cdc.write_port_;
void (*fun)(void *) = [](void *) {
LibXR::STDIO::Printf<"read count: %d, write count: %d, error count: %d\r\n">(
count_read, count_write, count_error);
LibXR::STDIO::Printf<"speed: %d BAUD\r\n">(
count_read * 10 * sizeof(write_buffer));
count_read = 0;
count_write = 0;
};
auto print_task =
LibXR::Timer::CreateTask(fun, reinterpret_cast<void *>(0), 1000);
LibXR::Timer::Add(print_task);
LibXR::Timer::Start(print_task);
void (*thread_read)(LibXR::UART *) = [](LibXR::UART *uart) {
LibXR::Semaphore sem(0);
LibXR::ReadOperation op(sem);
while (true) {
uart->Read(read_buffer, op);
if (LibXR::CRC8::Verify(read_buffer, sizeof(read_buffer))) {
count_read++;
} else {
count_error++;
}
}
};
void (*thread_write)(LibXR::UART *) = [](LibXR::UART *uart) {
LibXR::Semaphore sem(1);
LibXR::WriteOperation op(sem);
uart->SetConfig({BAUDRATE, LibXR::UART::Parity::NO_PARITY, 8, 1});
while (true) {
write_buffer[0]++;
write_buffer[sizeof(write_buffer) - 1] = LibXR::CRC8::Calculate(
write_buffer, sizeof(write_buffer) - sizeof(uint8_t));
uart->Write(write_buffer, op);
count_write++;
}
};
LibXR::Thread read_thread, write_thread;
read_thread.Create(reinterpret_cast<LibXR::UART *>(&usart1), thread_read,
"read_thread", 2048,
static_cast<LibXR::Thread::Priority>(4));
write_thread.Create(reinterpret_cast<LibXR::UART *>(&usart1), thread_write,
"write_thread", 2048,
static_cast<LibXR::Thread::Priority>(3));
while (true) {
LibXR::Thread::Sleep(UINT32_MAX);
}
速率测试
STM32F1 -0g 32字节 2M波特率
32字节接近实际的串口�数据包大小,在2M波特率下能够逼近串口理论速率。
read count: 6000, write count: 5999, error count: 0
speed: 1920000 BAUD
read count: 6000, write count: 6000, error count: 0
speed: 1920000 BAUD
read count: 5999, write count: 6000, error count: 0
speed: 1919680 BAUD
read count: 6000, write count: 5999, error count: 0
speed: 1920000 BAUD
read count: 6000, write count: 6000, error count: 0
speed: 1920000 BAUD
read count: 5999, write count: 6000, error count: 0
speed: 1919680 BAUD
STM32F1 -03 32字节 2M波特率
O3优化下没有明显区别
read count: 6000, write count: 5999, error count: 0
speed: 1920000 BAUD
read count: 5999, write count: 6000, error count: 0
speed: 1919680 BAUD
read count: 6000, write count: 6000, error count: 0
speed: 1920000 BAUD
read count: 6000, write count: 5999, error count: 0
speed: 1920000 BAUD
read count: 5999, write count: 6000, error count: 0
speed: 1919680 BAUD
read count: 6000, write count: 6000, error count: 0
speed: 1920000 BAUD
STM32F1 -0g 128字节 4M波特率
更大的数据包,更高的波特率
read count: 3061, write count: 3061, error count: 0
speed: 3918080 BAUD
read count: 3062, write count: 3062, error count: 0
speed: 3919360 BAUD
read count: 3062, write count: 3062, error count: 0
speed: 3919360 BAUD
read count: 3061, write count: 3061, error count: 0
speed: 3918080 BAUD
read count: 3062, write count: 3062, error count: 0
speed: 3919360 BAUD
read count: 3063, write count: 3062, error count: 0
speed: 3920640 BAUD
CH32V307 -Og 64字节 9M波特率
9M波特率下一样能够达到理论速率
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
read count: 14000, write count: 14000, error count: 0
speed: 8960000 BAUD
系统调用分析
再测速率已经没有意义了,这里使用STM32F4+SystemView展示收发过程的系统调用情况。本身收发过程完全无锁,所有的系统调用都为线程本身的唤醒和同步操作所需的信号量。
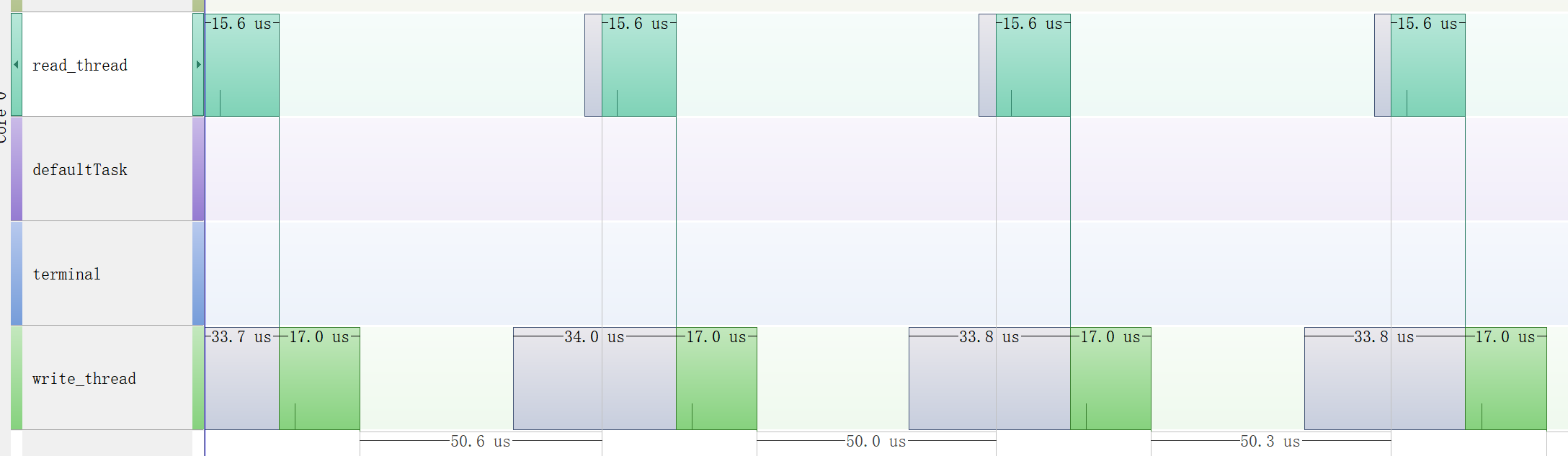
较低波特率
低波特率下多个包被连起来,无法触发IDLE中断。写线程周期性被唤醒,读线程等到半满/全满中断时被唤醒。
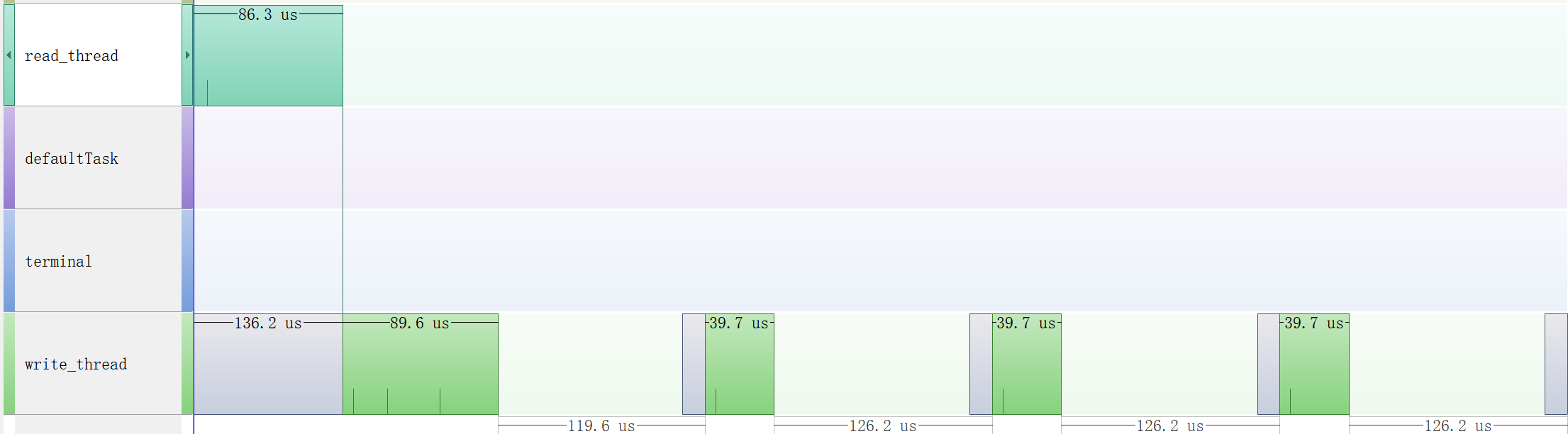
较高波特率
高波�特率下,一收一发两个线程轮流唤醒。
总结
LibXR 框架在对底层串口驱动进行封装后,在绝大多数情况下不会造成明显的性能损失。在在 STM32F103(72MHz)平台实测中,2~4 Mbps 波特率下数据收发稳定无误,最高实际吞吐接近物理上限,说明即便在低性能平台也具备高效性能表现,完全可用于对实时性与带宽有要求的应用。